

官网:https://sadtalker.github.io/
简介
SadTalker由西安交通大学的研究人员提出的,它可以让照片里的人物跟随音频的输入动起来,且头部运动、面部表情比较真实。
安装
Linux/Unix
1、安装 Anaconda、Python 和 git .
2、创建环境并安装依赖
git clone https://github.com/OpenTalker/SadTalker.git
cd SadTalker
conda create -n sadtalker python=3.8
conda activate sadtalker
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
conda install ffmpeg
pip install -r requirements.txt
### Coqui TTS is optional for gradio demo.
### pip install TTSWindows
中文Windows教程:
1、安装 Python 3.8 并选中“Add Python to PATH”。
2、‘手动安装 git 或使用 Scoop: scoop install git 安装。
3、下载FFmpeg,解压,并将其中的\bin目录加入到PATH。或者使用 scoop安装 ffmpeg 。 scoop install ffmpeg
4、通过运行 git clone https://github.com/Winfredy/SadTalker.git 下载 SadTalker 存储库。或者直接到GitHub下载zip文件。
macOS
此方法已在 M1 Mac (13.3) 上进行了测试
git clone https://github.com/OpenTalker/SadTalker.git
cd SadTalker
conda create -n sadtalker python=3.8
conda activate sadtalker
# install pytorch 2.0
pip install torch torchvision torchaudio
conda install ffmpeg
pip install -r requirements.txt
pip install dlib # macOS needs to install the original dlib.Docker
docker run --gpus "all" --rm -v $(pwd):/host_dir wawa9000/sadtalker \
--driven_audio /host_dir/deyu.wav \
--source_image /host_dir/image.jpg \
--expression_scale 1.0 \
--still \
--result_dir /host_dir下载模型
您可以在 Linux/macOS 上运行以下脚本来自动下载所有模型:
bash scripts/download_models.shwindows
预训练模型:
- Google Drive Google 云端硬盘
- GitHub Releases GitHub 版本
- Baidu (百度云盘) (Password:
sadt)
GFPGAN 离线补丁:
- Google Drive Google 云端硬盘
- GitHub Releases GitHub 版本
- Baidu (百度云盘) (Password:
sadt)
在软件下新建一个checkpoints文件夹,将上面下载的2个压缩包解压到该文件夹。
运行
在线演示
HuggingFace | SDWebUI-Colab | Colab
Linux/Mac OS
运行 bash webui.sh 以启动 webui。
Windows
只需双击 webui.bat ,依赖将自动安装。如果出现以下错误,可尝试把requirements.txt文件里的gradio==改成gradio==3.41.2。

作为Stable Diffusion WebUI 扩展运行
1、安装最新版本的 stable-diffusion-webui 并通过 extension 安装 SadTalker。

2、手动下载适用于 Linux 和 Mac 的模型:
cd SOMEWHERE_YOU_LIKE
bash <(wget -qO- https://raw.githubusercontent.com/Winfredy/OpenTalker/main/scripts/download_models.sh)Windows用户,在上面“下载模型”位置下载。
3.1. 选项 1:将检查点放入 stable-diffusion-webui/models/SadTalker 或 stable-diffusion-webui/extensions/SadTalker/checkpoints/ 中,将自动检测检查点。
3.2. 选项 2:通过以下方式设置 in webui_user.sh (linux) 或 webui_user.bat (windows) 的 SADTALKTER_CHECKPOINTS 路径:
> only works if you are directly starting webui from `webui_user.sh` or `webui_user.bat`.
```bash
# Windows (webui_user.bat)
set SADTALKER_CHECKPOINTS=D:\SadTalker\checkpoints
# Linux/macOS (webui_user.sh)
export SADTALKER_CHECKPOINTS=/path/to/SadTalker/checkpoints
```4、通过 webui.sh or webui_user.sh(linux) 或任何其他 webui_user.bat(windows) 方法启动 WebUI。SadTalker 也可以直接在 stable-diffusion-webui 中使用。

使用
启动后在windows中会在命令行界面,其他系统类似,浏览器中输入提供的地址进行访问进入软件。
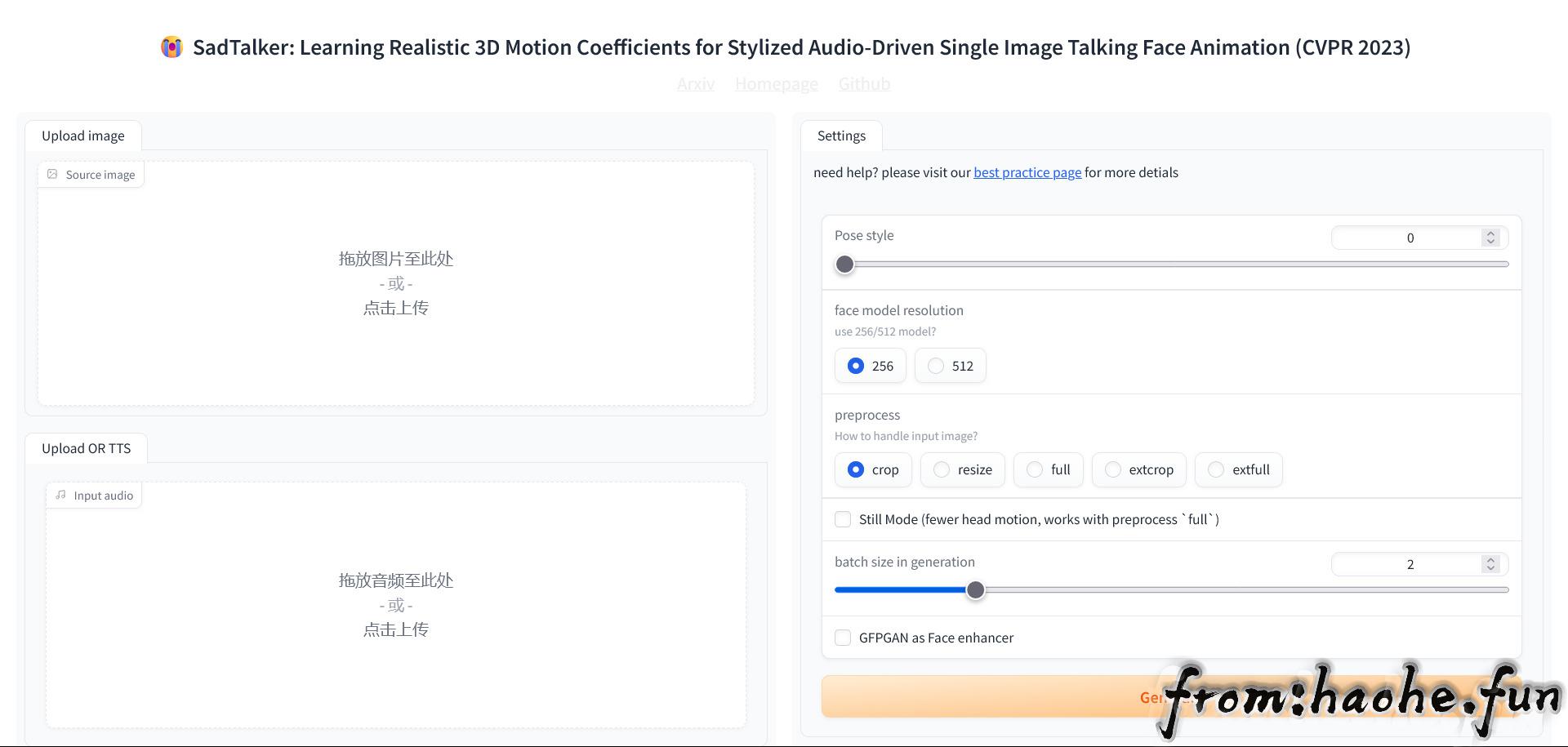
左边分别上传图片和音频文件,右边是具体设置:
Pose style:姿势,可以不修改,默认即可;
face model resolution:人物模型分辨率,图片一般清晰选256,特别清晰选512;
preprocess:处理方式,一般选crop(裁剪)或full(全身),crop即裁剪多余部分,只保留头部,full即不裁剪,保持原始画面;
Still Mode:静止模式,适用于上面选择full,勾选后图像不会做大动作,避免头部与身体分离。
batch size in generation:默认即可。
GFPGAN as Face enhancer:面部增强,可选可不选,勾选后效果会更好,但更耗时。
最后点击“Generate”就开始运行了,输出结果在results文件夹。


